声明:以下部分内容转载自“语言技术中心@HIT 语言技术紫丁香 ”
论文名称:Pseudo-Utterance-Guided Contrastive Network for Emotion Forecasting in Conversations
论文作者:解云鹤,孙承杰等
论文链接:https://doi.org/10.1016/j.eswa.2025.127382
转载需标注出处:哈工大计算学部语言技术研究中心
由哈工大语言技术中心完成、发表于Expert Systems with Applications(中科院1区Top期刊,SCI IF 7.5@2023)的这篇文章主要探索了对话情绪预测问题。对话中的情感预测(EFC)旨在根据对话历史和对话者的身份预测即将说出的话语的情感。传统的对话情感识别(ERC)可以获取完整的对话信息,而EFC则不同,它因语句内容缺失而面临更大的挑战。一些研究通过直接调整ERC 模型来解决EFC 问题,但这些适配后的模型往往因性能限制而仅能应用于简化场景中,此外忽略了标签噪声。此外,汇总对话历史记录的方法往往会模糊EFC 和ERC 之间的区别,从而使模型的决策过程缺乏可解释性。为了解决这些问题,本文提出了一种用于 EFC 的伪话语引导对比网络(PUGCN)。具体来说,本文首先在语篇编码阶段纳入对话者信息,以捕捉参与者轨迹,消除对话窗口大小等限制。接下来,本文采用有监督的对比学习来加强语义空间中不同情绪语句之间的分离,从而减轻噪声语句对未来预测的影响。此外,本文还引入了伪话语生成作为辅助任务,利用生成的伪话语来填补缺失的口语位置并指导 EFC 任务。在三个基准数据集上进行的广泛实验表明,本文提出的 PUGCN 明显优于基线模型。
1.研究动机
EFC 在实际应用中具有巨大潜力,但由于缺乏关键语篇,其有效性往往受到限制,从而使任务变得更具挑战性。其中许多研究忽略了对话者的基本信息,而且局限于过于简化的设置,对对话窗口大小和参与者人数都有限制[1]。此外,这些模型通常侧重于将语句表征映射到情绪标签上,而对标签噪声的处理却不够充分。虽然完整的对话记录可以缓解这一问题,但仅仅依靠历史数据会随着时间的推移扩散噪音,从而降低性能[2]。此外,直接汇总对话历史记录可能会模糊 EFC 和 ERC 任务之间的区别,从而影响清晰度并限制模型的改进[3]。本文的目标是减少不必要的模型约束,降低标签噪声的影响,并结合辅助信息来弥补缺失的语篇,从而使预测过程建立在更可靠的证据之上。
2.研究方法
本文提出的PUGCN 包括三个主要模块:对话者身份感知语篇编码模块、情感级对比学习模块和伪话语生成模块。本文利用BART 在分类和生成任务方面的强大能力作为特征提取的基础。在预训练任务中,首先用ERC 处理完整的对话记录以获取初始嵌入,并在 BART 分类模式下运行BART。在训练过程中,使用除目标语ui之外的对话历史记录作为主要EFC 任务和辅助伪话语生成任务的输入。在 EFC 任务中,对话者身份感知编码模块生成ui 的语篇级表示。然后,我们在转换器层中整合这些表征,得出对话级表征。情感级对比学习模块在解码模块中结合了对比损失和传统的交叉熵损失。对于伪话语生成任务,BART 会切换到 BART 生成模式,并生成一个伪预测话语ui 来替换ui,从而在整个预测过程中提供持续的指导。
3.数据集
本文在三个会话情感数据集上评估了PUGCN 的性能:MELD[4]、DailyDialog[5]和 EmoryNLP[6]。DailyDialog 涉及二方之间的互动,而 MELD 和 EmoryNLP 涉及多方对话。本文的实验分析侧重于从所有三个数据集的文本内容中提取情感特征。表 1 提供了这些数据集的详细信息。

由于直接应用 EFC 的数据集有限,且缺乏统一的评估标准,为了公平比较,本文采用了 DialogueGLP[7]的预处理和评估方法。对于大规模的 DailyDialog,本文将每段对话都视为一个独立的例子,并将最终语句的情感作为其标签。对于 MELD 和 EmoryNLP,本文将对话分割成至少三个语段的较小片段,并在对话者发生变化时进行分割,以增加训练实例。
4.实验结果及分析
表 2 列出了本文提出的 PUGCN 和基线模型在三个基准数据集上的总体结果。
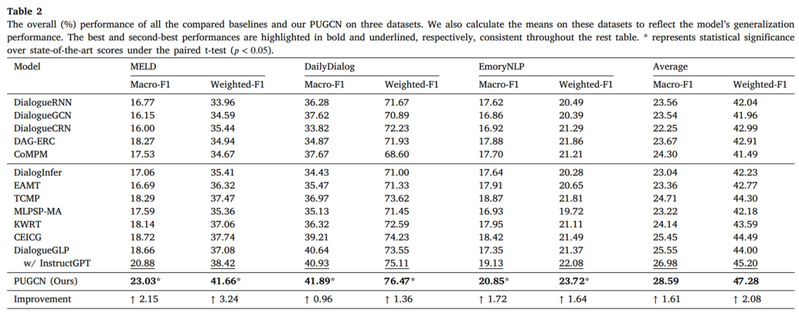
PUGCN在所有三个数据集上的表现都优于最先进的模型,整体性能提高了 2.08%。鉴于本文的方法不依赖额外的训练数据或外部知识源,这一改进尤其值得注意。MELD 的 3.24% 提升主要归功于其对话的多方性质,而 PUGCN 的对话者身份感知编码模块能有效捕捉复杂的情感轨迹,从而使其受益匪浅。此外,经过数据集预处理后,MELD 中每段对话的平均话语数低于 6 个,因此更容易受到语料标签噪声的影响。然而,PUGCN 的情感级对比学习模块有效地缓解了这一问题,从而产生了更稳健的情感表征。此外,PUGCN 在生成伪话语时遵循了对话的基本逻辑,确保了与评估数据更好地匹配,并以更低的资源成本实现了性能提升。
本文采用了各种方法来生成目标话语的替代物,从而证明了PUG模块的有效性。ConstantPad 用固定的占位符值替换目标语篇。在最大池化方法中,本文将对话窗口的大小设为3,并根据附近对话历史对目标语篇的影响更大这一观点,对该窗口内的语篇作为替代语篇的表征进行最大池化处理。在随机初始化方法中,本文随机生成多个初始化的伪话语表征,并计算它们的平均值作为最终结果。在评估上述方法性能的实验设置中,我们将 PUG 的权重系数设为 0,其他设置保持不变。
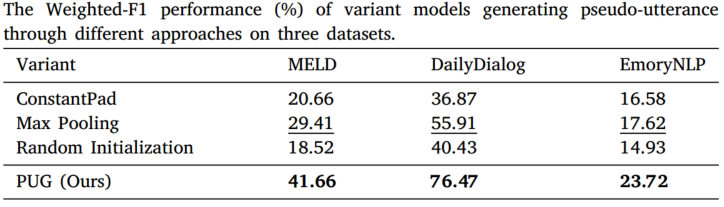
对表中所示结果的分析表明,ConstantPad 和随机初始化都明显降低了模型性能,这与本文的预期相符,因为这些方法都会引入大量噪声。与上述方法相比,最大池化变体的性能有所提高,支持了情绪传染理论。然而,它仍然无法与基线模型相提并论。相比之下,PUG 模块生成的伪话语合情感动态,并反映了对话历史的语境背景,因此性能优于其他变体。
5. 结论
本工作设计了一种伪话语引导对比网络以解决对话情绪预测问题。本文的方法通过整合对话者信息、利用对比学习技术以及结合辅助任务来提高预测准确性,从而应对了主要挑战。本文在三个基准数据集上进行了广泛的实验,平均提高了 2.08%,其中在 MELD 数据集上的提高最为显著,达到了 3.24%。消融研究表明,所有三个模块:对话者身份感知编码、情感级对比学习和伪话语成都对模型的性能做出了积极贡献。伪话语生成模块的整体影响最大,对话者身份感知编码模块在多方对话中表现出色,而情感水平对比学习模块在较短或随意对话中最为有效。对预测误差的详细统计分析显示,高频词块的相对频率和分布会影响模型的预测倾向。中等频率的词组尤其能有效地引导模型做出更准确的预测。
参考文献
[1] Zou, C., Yin, Y., & Huang, F. (2022). Attention-based emotion-assisted sentiment forecasting in dialogue. In 2022 international joint conference on neural networks (pp. 1–8). http://dx.doi.org/10.1109/IJCNN55064.2022.9892452.
[2] Xue, Y., Whitecross, K., & Mirzasoleiman, B. (2022). Investigating why contrastive learning benefits robustness against label noise. In International conference on machine learning (pp. 24851–24871). URL: https://proceedings.mlr.press/v162/ xue22a.html.
[3] Li, D., Zhu, X., Li, Y., Wang, S., Li, D., Liao, J., et al (2021). Emotion inference in multi-turn conversations with addressee-aware module and ensemble strategy. In Proceedings of the 2021 conference on empirical methods in natural language processing (pp. 3935–3941). http://dx.doi.org/10.18653/v1/2021.emnlp-main.320.
[4] Poria, S., Hazarika, D., Majumder, N., Naik, G., Cambria, E., & Mihalcea, R. (2019). MELD: A multimodal multi-party dataset for emotion recognition in conversations. In Proceedings of the 57th annual meeting of the association for computational linguistics (pp. 527–536). http://dx.doi.org/10.18653/v1/p19-1050.
[5] Li, Y., Su, H., Shen, X., Li, W., Cao, Z., & Niu, S. (2017). DailyDialog: A manually labelled multi-turn dialogue dataset. In Proceedings of the eighth international joint conference on natural language processing (Volume 1: Long papers) (pp. 986–995). URL: https://aclanthology.org/I17-1099/.
[6] Zahiri, S. M., & Choi, J. D. (2018). Emotion detection on tv show transcripts with sequence-based convolutional neural networks. In Workshops at the thirty-second aaai conference on artificial intelligence. URL: https://aaai.org/ocs/index.php/WS/ AAAIW18/paper/view/16434.
[7] Wang, R., & Feng, S. (2023). Global-local modeling with prompt-based knowledge enhancement for emotion inference in conversation. In Findings of the association for computational linguistics: EACL 2023 (pp. 2120–2127). http://dx.doi.org/10.18653/ v1/2023.findings-eacl.158.