声明:以下部分内容转载自“语言技术中心@HIT 语言技术紫丁香 ”
论文名称:
Re3MHQA: Retrieve, Remove, and Return facts in multi-hop QA
论文作者:曹子一,解云鹤,刘秉权,卜坤
论文链接:Expert Systems with Applications, 281, 127566.
https://www.sciencedirect.com/science/article/pii/S0957417425011881
转载需标注出处:哈工大计算学部语言技术研究中心
由哈工大语言技术中心完成、发表于Expert Systems with Applications(中科院1区Top期刊,SCI IF 7.5@2023)的这篇文章主要探索了多跳问答中的若干关键问题。在多跳问答(Multi-Hop QA)领域,如何有效地检索、处理和返回相关事实一直是研究热点。本文介绍的Re3MHQA方法,通过“检索(Retrieve)、移除(Remove)、返回(Return)”的创新流程,为多跳问答任务提供了新的解决方案,有望进一步提升问答系统的准确性和效率。
1、研究背景
多跳问答任务要求系统能够综合多个证据信息进行推理,以得出最终答案。与单跳问答不同,多跳问答需要多个检索步骤来收集支持回答的多个证据片段。然而,在检索过程中,可能会出现以下问题:一是检索到无效信息,这会干扰后续的检索方向;二是即使收集到必要的信息,仍可能进行不必要的检索步骤。此外,事实检索、错误识别和停止检索的判断通常是独立的功能,每个功能都需要至少一个模型,这导致了GPU资源的浪费。针对这些问题,本文提出了Re3MHQA框架。
2、Re3MHQA框架
Re3MHQA框架包含三个核心组件:Retrieve、Remove和Return。
(1)Retrieve:检索事实
Retrieve是一个类似双编码器的信息检索器,其主要任务是从知识库中检索与查询(和已检索事实)最相关的事实。在训练过程中,Retrieve针对事实和返回标志进行训练,以确保能够准确地检索到所需的事实。
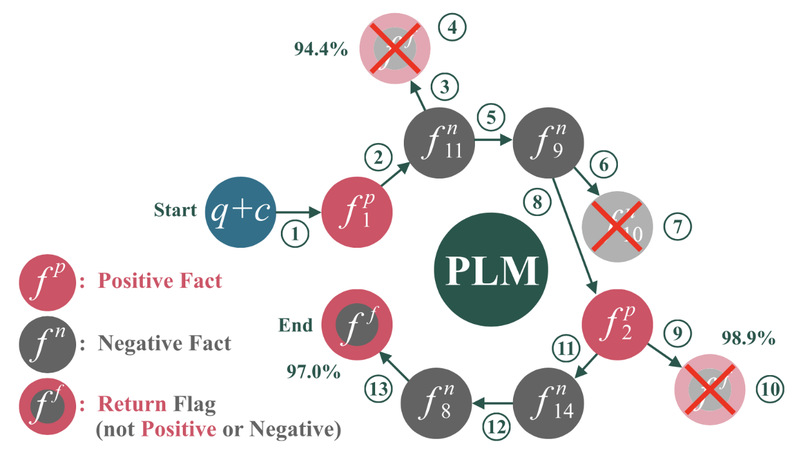
图1. Re3MHQA检索过程
2)Remove:移除无效事实
Remove基于交叉编码器策略,用于检查最新检索到的事实是否有效。如果检查结果为假,则移除该事实,以避免其干扰后续检索。Remove在每次检索后都会对最新事实进行检查,且随着检索步骤的增加,检查会更加严格。例如,在图1中, 被检索到后,Remove检查其在各个位置出现的概率,发现其多次低于设定阈值,因此将其移除。
被检索到后,Remove检查其在各个位置出现的概率,发现其多次低于设定阈值,因此将其移除。
(3)Return:返回事实并停止检索
Return同样基于交叉编码器策略,用于判断是否满足停止检索的条件并返回所有已收集的事实。当检索到返回标志时,Return会对其进行检查,只有当检查结果为真时才会停止检索并返回事实。例如,在图1中,Return在多次检查后发现继续检索的概率呈下降趋势,因此决定停止检索并返回已收集的事实。
3、实验结果及分析
本文在QASC和MultiRC两个数据集上对Re3MHQA进行了评估。
(1)QASC数据集
QASC数据集包含9980个问题,分为训练集(8134个)、验证集(926个)和测试集(920个)。每个问题都标注了两个用于回答问题的事实。实验结果显示,Re3MHQA在Recall#=2(找到两个真实事实的召回率)和F1指标上均优于已发表的检索方法。例如,在Total-K为2.5时,Re3MHQA的F1值达到了49.2,而其他方法的F1值大多低于40。
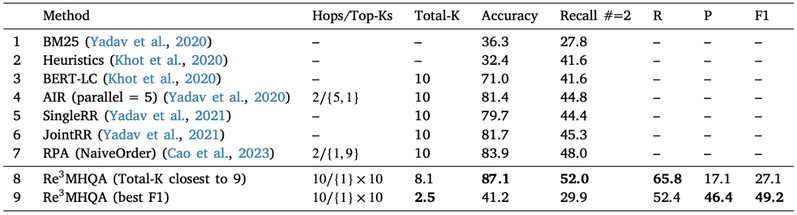
表1 QASC数据集上的表现
(2)MultiRC数据集
MultiRC数据集包含6000个问题,覆盖七个领域,需要对多个句子进行推理。实验结果表明,Re3MHQA在F1指标上取得了最佳性能,达到了73.6,超过了其他方法。这表明Re3MHQA能够有效地减少检索到的事实数量,同时提高检索质量。
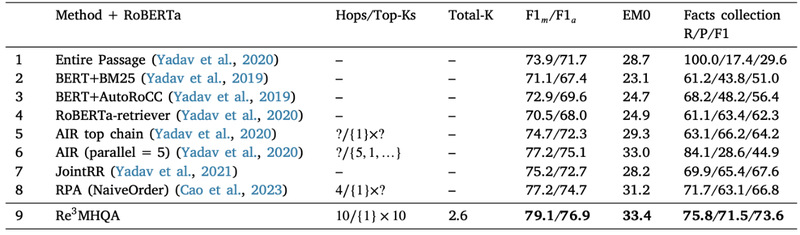
表2 MultiRC数据集上的表现
4、结论
Re3MHQA通过Retrieve、Remove和Return三个组件的协同工作,显著提升了多跳问答任务中的事实检索性能。Remove和Return组件能够有效地识别无效事实和停止标志,从而在获取相同数量事实的情况下,比单独的Retrieve方法取得更好的效果。此外,Re3MHQA基于一个预训练语言模型(PLM)实现所有组件的嵌入,提高了PLM的复用性,同时显著减少了GPU内存的使用。未来,作者计划将Re3MHQA与大型语言模型(LLM)结合,形成完整的LLM推理系统。
参考文献
[1] Yang, Z., Qi, P., Zhang, S., Bengio, Y., Cohen, W., Salakhutdinov, R., & Manning, C. D. (2018). HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (pp. 2369-2380).
[2] Asai, A., Hashimoto, K., Hajishirzi, H., Socher, R., & Xiong, C. (2019). Learning to retrieve reasoning paths over wikipedia graph for question answering. arXiv preprint arXiv:1911.10470.
[3] Das, R., Dhuliawala, S., Zaheer, M., & McCallum, A. (2019). Multi-step retriever-reader interaction for scalable open-domain question answering. arXiv preprint arXiv:1905.05733.
[4] Khot, T., Clark, P., Guerquin, M., Jansen, P., & Sabharwal, A. (2020, April). Qasc: A dataset for question answering via sentence composition. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 34, No. 05, pp. 8082-8090).
[5] Khashabi, D., Chaturvedi, S., Roth, M., Upadhyay, S., & Roth, D. (2018, June). Looking beyond the surface: A challenge set for reading comprehension over multiple sentences. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) (pp. 252-262).