论文标题:TextlessRAG: END-TO-END VISUAL DOCUMENT RAG BY SPEECH WITHOUT TEXT
论文作者:谢佩锦,钱顺,刘秉权,王德新,孙林,张向征
论文链接:https://github.com/xiepeijinhit-hue/textlessrag
https://ieeexplore.ieee.org/abstract/document/11462642
1. 导读
近日,哈尔滨工业大学ITNLP实验室与奇虎360智脑AI实验室合作完成的论文“TextlessRAG: END-TO-END VISUAL DOCUMENT RAG BY SPEECH WITHOUT TEXT”被语音与信号处理领域顶级会议ICASSP 2026(CCF-B类会议)正式录用。该研究提出了首个端到端全去文本化(Fully Textless)语音视觉文档检索增强生成框架,彻底消除了传统流水线对ASR、TTS和OCR模块的依赖,在多个基准测试上取得了显著的性能提升与效率优化。
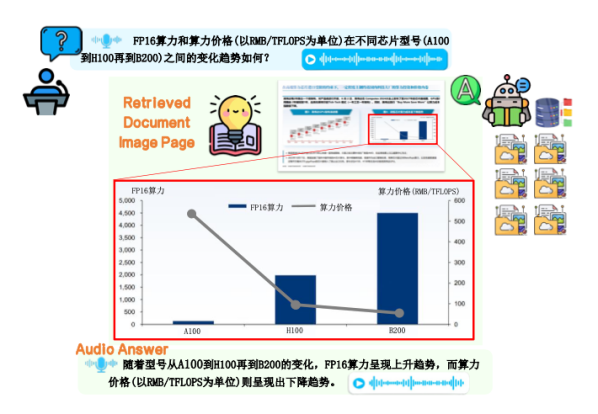
[图1: 方法总览]
2. 研究背景
检索增强生成(Retrieval-Augmented Generation, RAG)技术在知识密集型任务中展现了强大的能力,能够通过检索外部知识库来增强大语言模型的回答质量。然而,现有的RAG系统在处理语音输入和视觉文档时面临着显著的局限性。
传统的语音-文档问答流水线通常采用级联架构:首先使用自动语音识别(ASR)将语音转换为文本,然后利用光学字符识别(OCR)提取文档中的文字内容,最后在生成阶段再通过文本转语音(TTS)输出结果。这种”语音→文本→语音”的冗长处理链条不仅引入了累积的误差传播问题,还带来了高昂的计算开销和推理延迟。更为关键的是,OCR在处理复杂版式文档(如图表、表格、多栏排版)时性能急剧下降,严重制约了系统的实用性。
针对上述挑战,本研究提出了TextlessRAG框架,旨在构建一个真正意义上的端到端语音视觉文档RAG系统,实现”语音进、语音出”的全去文本化交互范式。
3. 技术方法
3.1 TextlessRAG整体架构
TextlessRAG框架的核心设计理念是完全绕过文本中间表示,直接在语音和视觉模态之间建立端到端的映射关系。整个系统由三个关键模块构成:语音-视觉联合编码器、布局感知重排序器和多模态生成器。
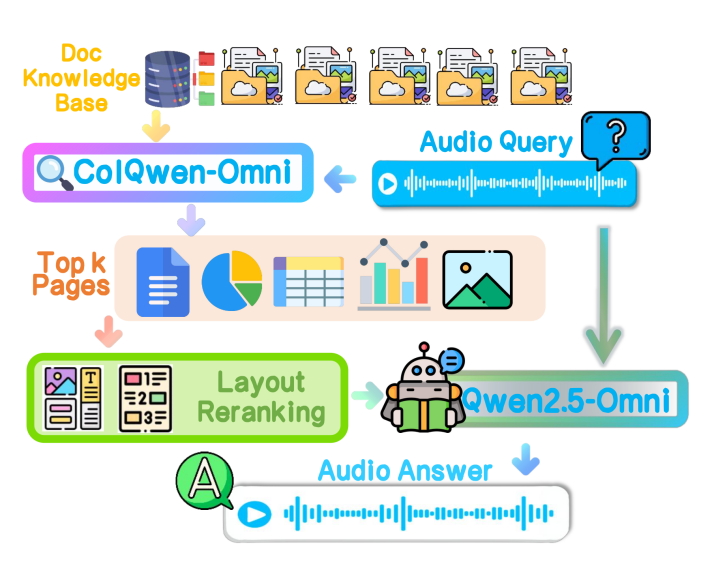
[图2: Pipeline流程图]
在检索阶段,框架采用ColQwen-Omni作为统一编码器,能够将语音查询和文档图像直接转换为高维嵌入向量,无需经过ASR或OCR的文本转换步骤。这种设计不仅大幅降低了推理延迟,还有效避免了级联误差的累积。
3.2 布局感知重排序机制
针对复杂版式文档的精确检索需求,TextlessRAG创新性地引入了布局感知重排序机制(Layout-aware Reranking)。该机制利用DocLayout-YOLO模型对候选文档页面进行版式分析,将页面分解为多种细粒度的证据单元类型:
证据单元类型 | 说明 |
图表(Charts) | 包含数据可视化的统计图表 |
表格(Tables) | 结构化的表格数据 |
自然图像(Natural Images) | 文档中嵌入的照片或插图 |
文本段落(Text Blocks) | 连续的文字段落区域 |
通过这种块级(Block-level)检索策略,系统能够精确定位与查询最相关的证据单元,显著提升了检索的精准度和召回率。
3.3 端到端生成架构
在生成阶段,TextlessRAG采用Qwen2.5-Omni作为多模态生成器,直接接收语音查询和经重排序后的视觉证据图像,输出语音形式的回答。整个过程完全绕过文本表示,实现了真正意义上的端到端语音-视觉交互。
4. SV-DOC基准数据集
为了系统性地评估语音视觉文档RAG系统的性能,研究团队发布了SV-DOC(Speech-Visual Document)——首个面向该任务的双语基准测试集。
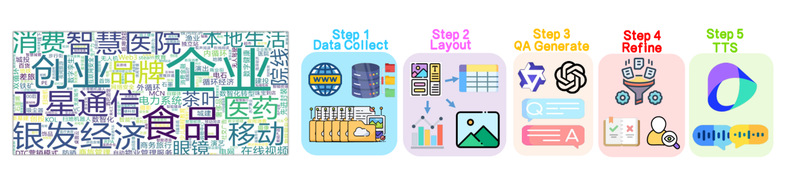
[图3: SV-DOC数据集构建]
SV-DOC数据集具有以下特点:
数据集特性 | 具体内容 |
语言覆盖 | 中文、英文双语支持 |
数据来源 | 整合多个公开文档理解数据集 |
标注质量 | 包含手工标注的中文文档RAG数据集(CDR) |
任务类型 | 涵盖检索、问答、推理等多种评测维度 |
CDR数据集的发布填补了中文语音视觉文档RAG领域的评测空白,为后续研究提供了重要的基准参照。
5. 实验结果
5.1 主要性能指标
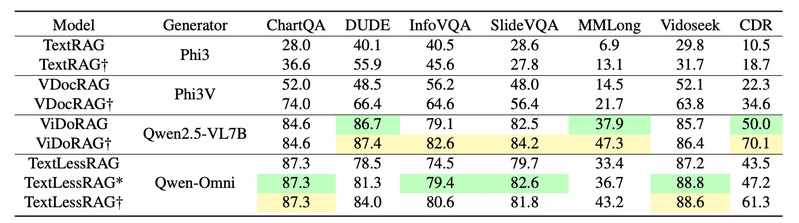
研究团队在多个权威基准测试上对TextlessRAG进行了全面评估,实验结果表明该框架在检索准确率和问答性能上均取得了优异表现。
评估基准 | TextlessRAG得分 | 性能表现 |
ChartQA | 87.3 | 图表问答任务达到领先水平 |
Vidoseek | 88.8 | 视频文档检索任务最佳 |
检索性能 | — | 显著优于BM25、E5等文本方法 |
[表1: 检索实验结果分析]
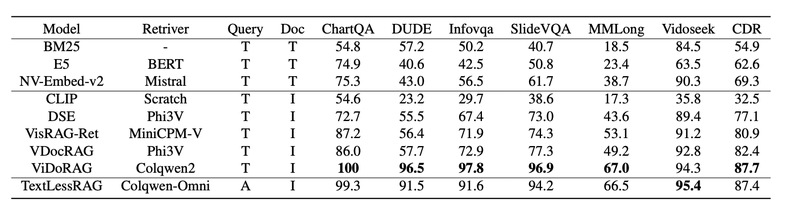
[表2: 问答实验结果分析]
5.2 效率分析
与传统级联式架构相比,TextlessRAG在推理效率方面展现出显著优势。通过消除ASR/OCR/TTS的串行处理开销,系统大幅降低了端到端推理延迟,在速度与准确率之间取得了优异的平衡。实验数据表明,TextlessRAG能够在保持高准确率的同时实现显著的速度提升,充分验证了全去文本化架构的可行性与优越性。
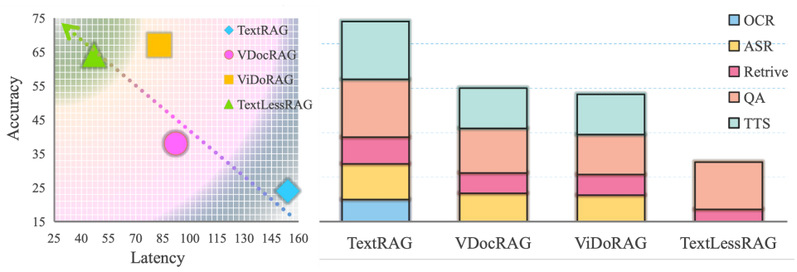
[图4: 效率分析]
6. 结论与展望
本研究提出的TextlessRAG框架在语音视觉文档RAG领域实现了三项重要突破:
1. 架构创新:首次构建了完全去文本化的端到端语音视觉文档RAG流水线,彻底摆脱了对ASR/OCR/TTS模块的依赖
2. 技术创新:提出布局感知重排序机制,实现了复杂版式文档的细粒度块级检索
3. 资源贡献:发布SV-DOC首个双语语音视觉文档RAG基准数据集,推动该领域的标准化评测
该研究为构建下一代自然、高效的人机交互系统提供了重要的技术参考,在智能文档处理、语音助手、多模态搜索等应用场景中具有广阔的落地前景。
7. 参考文献
[1] ICASSP 2026. IEEE International Conference on Acoustics, Speech and Signal Processing. https://2026.ieeeicassp.org/