论文名称:Modeling Both Intra- and Inter-Utterance Variability for Conversational Emotion Recognition
论文作者:付雨濛;商守铎;吴俊劼;张梅山;刘秉权
论文链接:https://ieeexplore.ieee.org/document/11462775
由哈工大计算学部语言技术研究中心ITNLP研究室完成,并发表于 ICASSP 的这篇文章主要用于解决对话情绪识别中语音信息利用不足的问题。对话情绪识别(Conversational Emotion Recognition, ERC)旨在识别多轮对话中每句话所表达的情绪,是智能客服、社交机器人和人机交互等场景中的关键技术。然而,现有基于大语言模型的方法多侧重文本内容,对语音中的音高、音量、语速、节奏等情绪线索,以及话语之间的结构关系建模不足。本文提出了一种多模态变异学习网络 MM-VLN,将话语内部语音变化与话语间结构关系共同建模,并通过图神经网络和轻量级 Adapter 将结构化语音信息注入大语言模型,有效提升了模型对真实对话情绪变化的理解能力。实验结果表明,该方法在IEMOCAP和MELD两个公开数据集上均取得优良性能,验证了结构化语音信息对对话情绪识别任务的重要作用。
让大模型真正“听懂”对话情绪:我们提出 MM-VLN,建模对话中的语音变化与结构关系。
在真实交流中,情绪并不只藏在文字里。同一句话,用不同的语速、音量、音高和节奏表达,可能传递出完全不同的情绪;而一次对话中的情绪变化,也往往不是孤立发生的,而是受到上下文、说话人互动以及前后话语关系的影响。围绕这一问题,我们的工作“Modeling Both Intra- and Inter-Utterance Variability for Conversational Emotion Recognition” 提出了一种新的多模态情绪识别框架MM-VLN,用于帮助大语言模型更充分地理解对话中的语音情绪线索。
一、研究背景:为什么对话情绪识别不能只看文字?
对话情绪识别,目标是判断对话中每一句话所表达的情绪,例如高兴、愤怒、悲伤、中立、惊讶等。这一任务在智能客服、社交机器人、推荐系统、人机交互等场景中具有重要应用价值。近年来,大语言模型在自然语言理解任务中表现突出,也推动了对话情绪识别的发展。已有方法通常通过提示词、上下文建模或指令微调,让模型根据文本内容和说话人信息进行情绪判断。但是,真实对话中的情绪远不止文本本身。例如,一句“我没事”,如果语速缓慢、音量低、音调下沉,可能表达的是悲伤或失落;如果语调急促、音量提高,则可能暗含愤怒或不满。也就是说,语音中的音高、音量、语速、节奏等信息,是判断情绪的重要依据。更进一步,情绪还具有明显的上下文关联。当前话语的情绪可能依赖于前面较远的一句话,而不是只受相邻话语影响。因此,仅仅提取单句语音特征还不够,还需要建模话语之间的结构关系。
基于此,我们关注两个关键问题:
第一,如何刻画单句话语内部的语音变化?
例如音量、音高、语速和节奏如何体现情绪强度与情绪类别。
第二,如何建模多轮对话中话语之间的情绪关联?
例如情绪是否延续、转折,或者受到前文某一句话的影响。
这正是本文试图解决的核心问题。
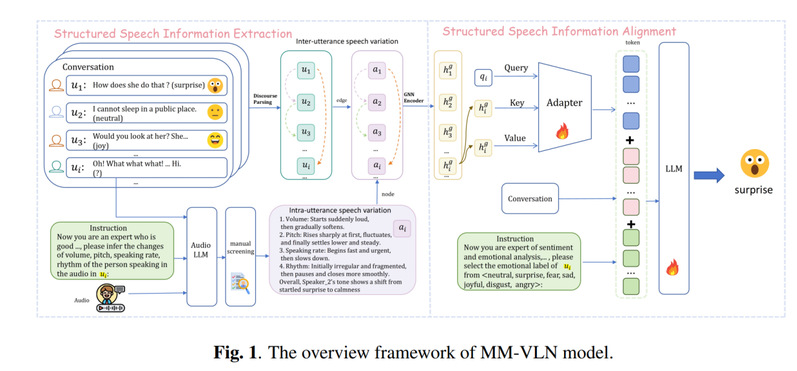
二、研究方法:用“结构化语音信息”增强大语言模型
MM-VLN 的核心思想是:将对话中的语音变化信息和话语结构信息组织成图结构,再对齐到大语言模型的表示空间中,从而增强模型的情绪理解能力。
整体方法可以分为三个步骤。
1. 提取话语内部语音变化
首先,模型利用音频大模型提取每一句话中的语音变化信息,包括:
· 音量变化
· 音高变化
· 语速变化
· 节奏变化
这些信息被转化为文本形式的语音描述,用于刻画单句话语内部的情绪线索。
2. 建模话语之间的结构关系
其次,MM-VLN 不只关注每一句话本身,还进一步分析对话中不同话语之间的依赖关系。
论文中使用对话篇章解析模型来获得话语之间的结构连接。例如,某一句话可能是对前面某句话的回应、解释或情绪延续。这些关系能够帮助模型理解当前情绪产生的上下文来源。
在 MM-VLN 中:
· 每一句话的语音变化信息被建模为图中的节点;
· 话语之间的篇章结构关系被建模为图中的边。
这样,整段对话就被表示成一个包含语音变化和结构关系的图。
3. 通过 GNN 与 Adapter 将结构信息注入 LLM
在得到图结构后,MM-VLN 使用图神经网络对结构化语音信息进行编码。
具体来说,论文采用 Graph Attention Network,即 GAT,作为图编码器。GAT 的优势在于,它可以为不同邻居节点分配不同权重,从而更灵活地建模哪些话语对当前情绪判断更重要。
随后,模型通过轻量级 Adapter 将 GNN 编码后的结构化语音表示投影到大语言模型的嵌入空间中,并作为一种“graph token”与文本表示拼接。
最后,大语言模型同时接收:
· 对话文本信息;
· 结构化语音信息;
· 上下文关系信息。
在此基础上,模型完成每一句话的情绪预测。简而言之,MM-VLN 的创新点在于:不是简单地把音频转成文本描述后交给大模型,而是进一步把语音变化和对话结构组织成图,再将图表示对齐到大模型中。这使模型不仅能“读懂”文字,也能更好地“听懂”语气,并理解情绪在多轮对话中的传递和变化。
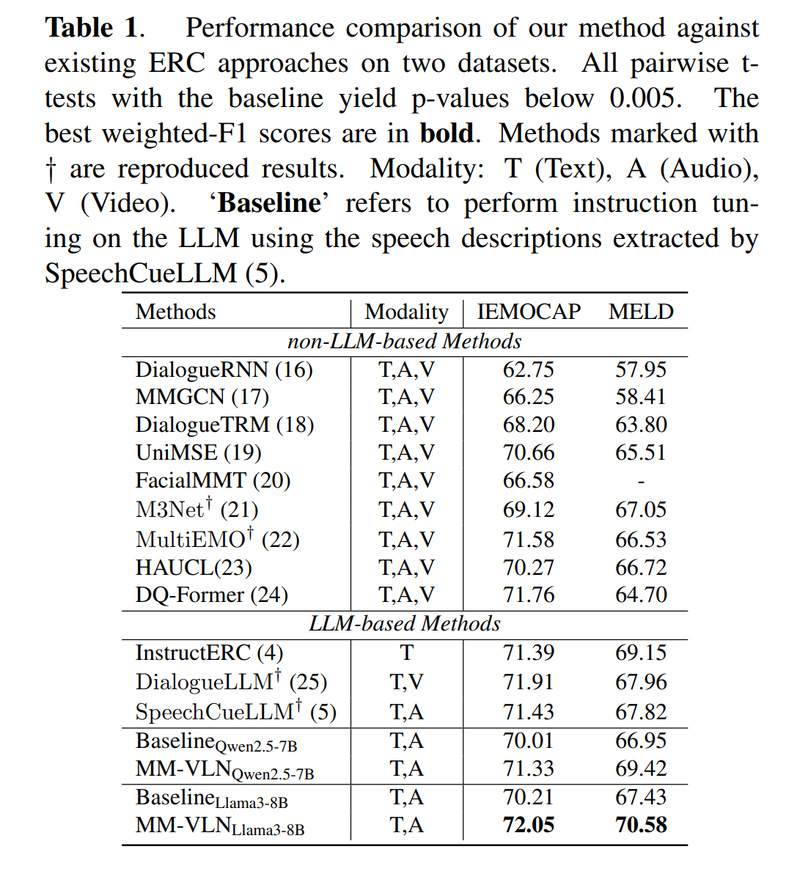
三、实验结果:在两个公开数据集上取得领先性能
为了验证方法有效性,论文在两个广泛使用的对话情绪识别数据集上进行了实验:
评价指标采用加权平均 F1 值,即 weighted-F1,这是对话情绪识别任务中常用的性能指标。
实验结果显示,MM-VLN 在两个数据集上均取得了最佳表现。
在IEMOCAP 数据集上,MM-VLN 达到 72.05% 的 weighted-F1;
在MELD 数据集上,MM-VLN 达到 70.58% 的 weighted-F1。
相比基线方法,MM-VLN 在 Llama3-8B 上分别带来了:
· IEMOCAP:提升 1.84%
· MELD:提升 3.15%
相比已有的基于LLM-based的语音对话情绪识别方法 SpeechCueLLM,MM-VLN 也分别提升了:
· IEMOCAP:提升 0.62%
· MELD:提升 2.76%
这说明,仅仅引入语音描述还不够,进一步建模语音变化之间的结构关系,能够为大语言模型提供更有效的情绪判断依据。
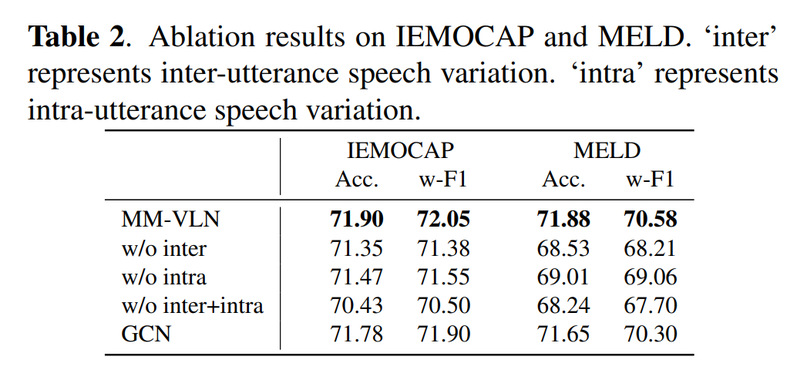
论文还进行了消融实验。结果表明:
· 去掉话语内部语音变化,性能会下降;
· 去掉话语之间结构关系,性能也会下降;
· 同时去掉二者,性能下降最明显。
这验证了两个结论:
第一,单句话语内部的语音变化对情绪识别很重要。
它提供了细粒度的情绪强度和情绪类别线索。
第二,多轮对话之间的结构关系同样关键。
它帮助模型理解情绪如何在上下文中延续、转折或触发。
参考文献
[1] Zehui Wu, Ziwei Gong, Lin Ai, Pengyuan Shi, Kaan Donbekci, and Julia Hirschberg, “Beyond silent letters: Amplifying llms in emotion recognition with vocal nuances,” arXiv preprint arXiv:2407.21315, 2024.
[2] Yazhou Zhang, Mengyao Wang, Prayag Tiwari, Qiuchi Li, Benyou Wang, and Jing Qin, “Dialoguellm: Context and emotion knowledgetuned llama models for emotion recognition in conversations,” arXiv preprint arXiv:2310.11374, 2023.
[3] Zijian Yi, Ziming Zhao, Zhishu Shen, and Tiehua Zhang, “Multimodal fusion via hypergraph autoencoder and contrastive learning for emotion recognition in conversation,” in Proceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 4341–4348.
[4] Jingwen Hu, Yuchen Liu, Jinming Zhao, and Qin Jin, “Mmgcn: Multimodal fusion via deep graph convolution network for emotion recognition in conversation,” in ACL, 2021, pp. 5666–5675.
[5] Ye Jing and Xinpei Zhao, “Dq-former: Querying transformer with dynamic modality priority for cognitive-aligned multimodal emotion recognition in conversation,” in Proceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 4795–4804.